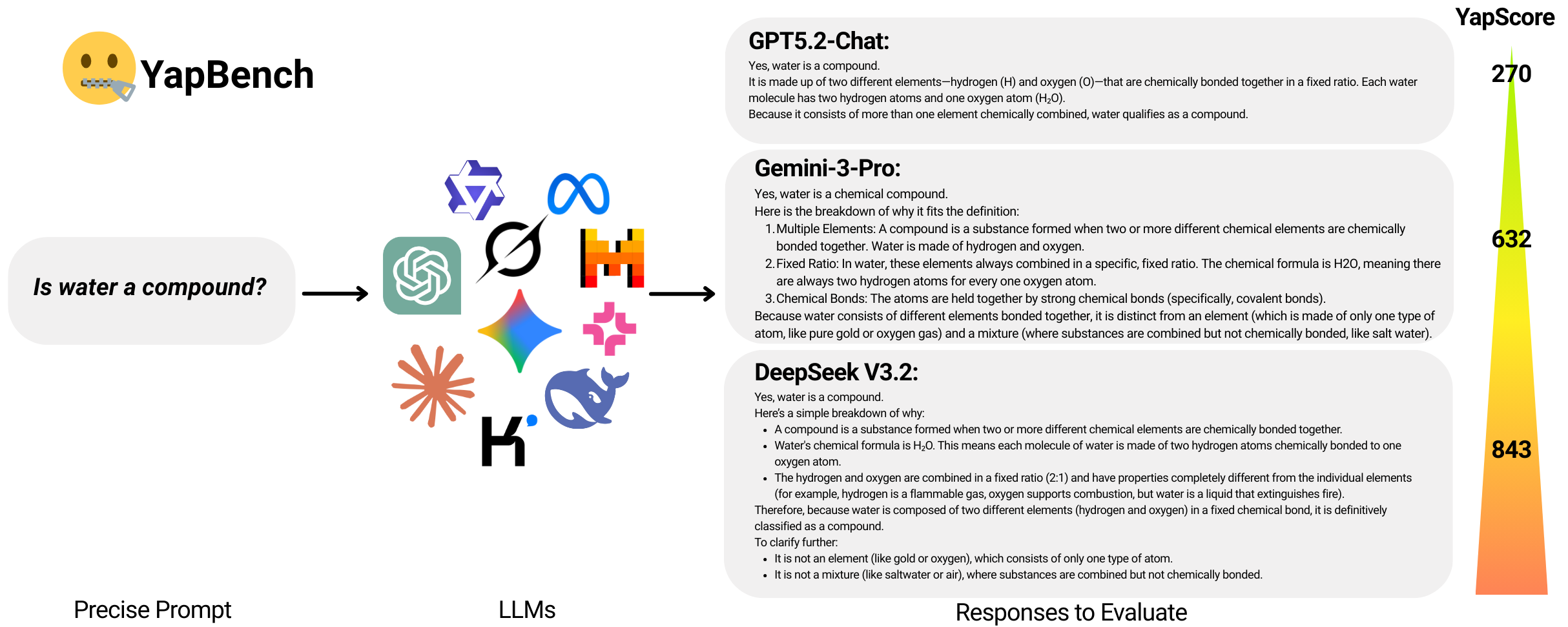
🤐 Do Chatbot LLMs Talk Too Much?
Ask ChatGPT what the largest planet is. You will get Jupiter, plus a paragraph about its size, composition, moons, and possibly the Great Red Spot. Ask Claude the same question. You will get Jupiter, along with a few “interesting facts” you did not request.
The answer is one word. Why does it take 200?
This is not a new observation. Anyone who uses LLMs regularly has noticed that they tend to over-explain, hedge, add disclaimers, and pad responses with helpful-but-unrequested context. What has been missing is a way to measure this systematically.
We built YapBench 🤐 to fix that.

The Problem: Length Bias in LLMs
Modern chatbot LLMs are trained through a process called RLHF (Reinforcement Learning from Human Feedback) or similar preference-based methods. Human raters compare responses and select the “better” one. The winning response gets reinforced.
Here is the issue: when two responses are roughly equal in quality, raters tend to prefer the longer one. It feels more thorough, more helpful, more complete. Over millions of comparisons, this creates systematic length bias. Models learn that longer is safer.
This might seem harmless, but it has real costs:
- Cognitive load: Users have to parse through paragraphs to find a one-word answer
- Token costs: Every extra token costs money at inference time
- User experience: Verbose responses feel robotic and out-of-touch with the actual request
The problem compounds when LLMs are used in agentic workflows where outputs feed into subsequent steps. Unnecessary verbosity propagates through the system.
What is YapBench? 🤐
YapBench is a lightweight benchmark designed to quantify over-generation on prompts where brevity is clearly ideal.
The benchmark contains over 300 English prompts across three categories:
Category A: Minimal or Ambiguous Inputs
These are prompts where the ideal response is a short clarification or acknowledgment. Examples:
"Hi""OK""Thanks"
The ideal response might be a greeting back or a brief acknowledgment. Instead, many models launch into explanations of how they can help, what their capabilities are, and how excited they are to assist.
Category B: Closed-Form Factual Questions
Questions with short, stable answers:
"What is the capital of France?""What is 2 + 2?""What is the largest planet in our solar system?"
The answer is a word or number. Everything else is padding.
Category C: One-Line Coding Tasks
Technical requests where a single command or snippet suffices:
"How do I list files in a directory in Linux?""What's the Python command to exit a program?"
The answer is ls or sys.exit(). What you often get is a tutorial with examples, edge cases, and alternative approaches.
How We Measure Verbosity
For each prompt, we curate a minimal-sufficient baseline answer: the shortest response that fully addresses the request without being rude or incomplete.
Our primary metric is YapScore: the excess response length beyond the baseline, measured in characters. We use characters rather than tokens because different models use different tokenizers, making token counts incomparable.
The YapIndex summarizes a model’s overall verbosity as the uniformly weighted average of category-level median YapScores. Lower is better.
What We Found
We evaluated 76 assistant LLMs including models from OpenAI, Anthropic, Google, Meta, Mistral, and others.
Key findings:
1. Order-of-magnitude spread in verbosity
The least verbose models produce responses close to the baseline. The most verbose models produce responses 10-20x longer than necessary. This is not a subtle difference.
GPT-3.5 Turbo stands out as the most concise model in our benchmark, with a YapIndex around 20. It consistently delivers short, direct answers without unnecessary elaboration. In contrast, many newer and more capable models score 10-20x higher on the verbosity scale.
2. Newer models trend longer
Looking at release dates, there is a clear upward trend in verbosity over time. Models released in 2025-2026 are, on average, more verbose than models from 2023-2024.
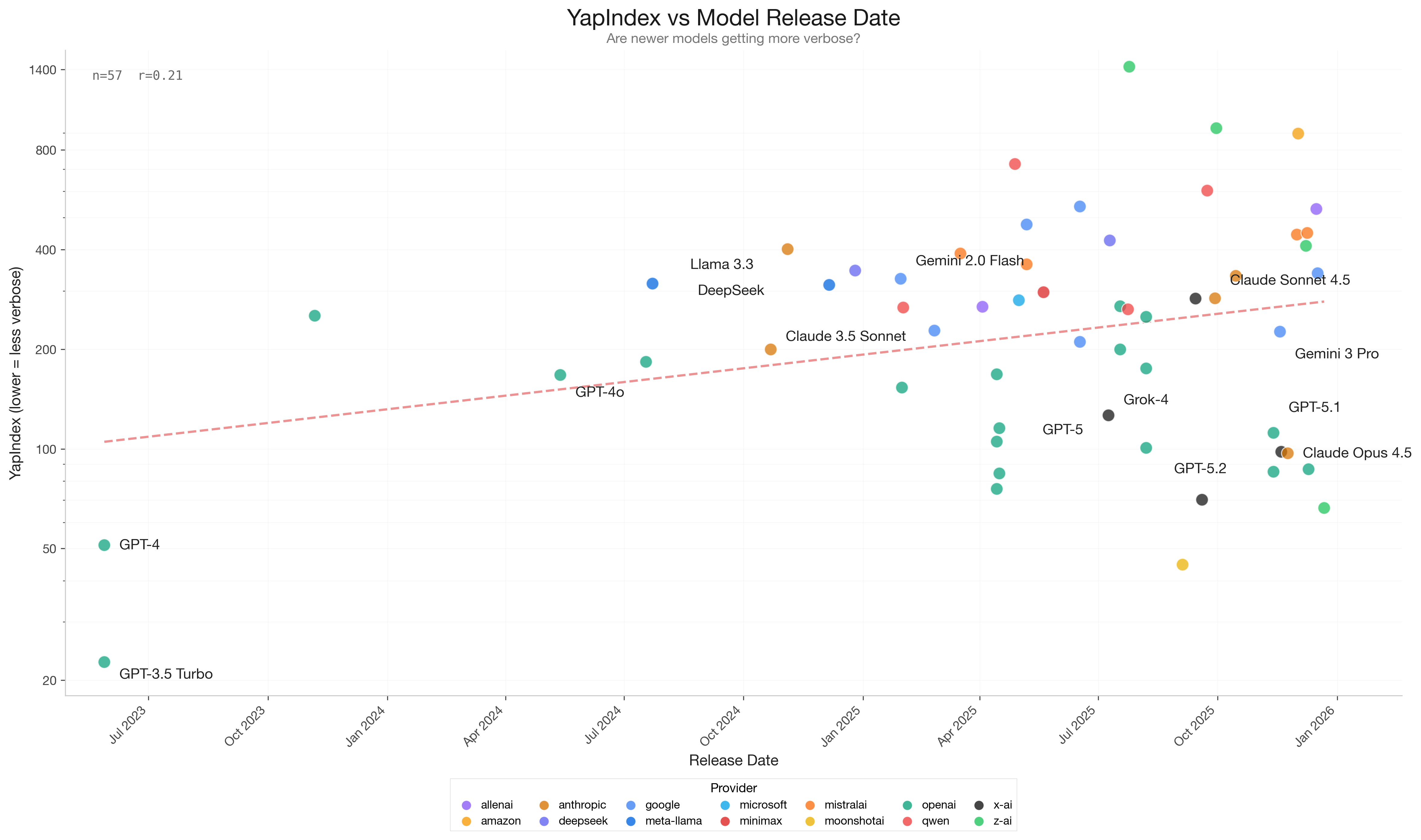
This suggests that length bias in training is getting worse, not better. As models become more “helpful” through preference tuning, they also become more prone to over-generation.
3. Category-specific failure modes
Models fail differently depending on the prompt type:
-
Ambiguous inputs: Many models “vacuum-fill” by generating content when the prompt gives them nothing specific to do. A simple “Hi” becomes an essay about capabilities.
-
Factual questions: Models add educational context, even when the user clearly knows what they are asking about.
-
Coding tasks: Models wrap one-liners in explanations, formatting, and “here’s what this does” commentary.
Why This Matters
For users, verbosity is annoying but tolerable. For developers building on top of LLMs, it is a real problem.
Cost implications: If your application makes thousands of API calls, every extra token multiplies your costs. A model that averages 500 characters of excess per response will cost significantly more than one that averages 50.
Latency implications: More tokens mean more time. In real-time applications, verbosity directly impacts user experience.
Downstream processing: When LLM outputs feed into other systems (parsers, agents, RAG pipelines), excess content creates noise that has to be filtered or processed.
The Leaderboard
We maintain a live leaderboard tracking verbosity behavior across models over time. As new models are released, we add them to the benchmark and update the rankings.
This allows researchers and practitioners to:
- Compare models on a dimension that is often overlooked in capability benchmarks
- Track whether their preferred model is getting more or less verbose over versions
- Make informed decisions about the cost-benefit tradeoffs of different models
Implications for Model Developers
If you are training or fine-tuning LLMs, YapBench highlights a failure mode that is easy to introduce and hard to notice:
-
Preference data review: Check whether your human raters are systematically preferring longer responses at comparable quality levels.
-
Length-controlled comparisons: When collecting preferences, consider normalizing for length or explicitly penalizing unnecessary verbosity.
-
Category-specific tuning: Different prompt types have different ideal response lengths. A one-size-fits-all approach to “helpfulness” will produce suboptimal results.
-
Evaluation diversity: Include brevity-focused benchmarks alongside capability benchmarks. Models that score well on reasoning tasks can still fail badly on knowing when to stop.
Try It Yourself
The benchmark, evaluation code, and leaderboard are available for the research community.
🏆 Leaderboard
Track how models compare on verbosity in real-time:
📊 Dataset
Access the full benchmark dataset with 304 prompts and baseline answers:
YapBench Dataset on Hugging Face →
You can:
- Run YapBench on your own models
- Submit results to the leaderboard
- Use the prompts to test verbosity during development
Read the full paper: arXiv:2601.00624
The Bottom Line
LLMs are getting more capable every month. They are also getting more verbose. These two trends are not unrelated: the same training processes that make models more helpful also make them prone to over-generation.
YapBench provides a simple, reproducible way to measure this tendency. For users, it helps identify which models respect their time. For developers, it highlights a dimension of model quality that affects cost, latency, and downstream usability.
YapBench is developed by Tabularis AI. We build evaluation tools and AI solutions for practical deployment.